Set Up Crons
Sentry Crons allows you to monitor the uptime and performance of any scheduled, recurring job in your application.
Once implemented, it'll allow you to get alerts and metrics to help you solve errors, detect timeouts, and prevent disruptions to your service.
- Use our getting started guide to install and configure the Sentry Elixir SDK (min v10.2.0) for your recurring job.
- Create and configure your first monitor.
If you're using Oban or Quantum, Sentry can automatically capture check-ins for all jobs that are scheduled to run periodically. To achieve this, you need to enable the corresponding Sentry plugin:
config :sentry,
integrations: [
oban: [cron: [enabled: true]],
# Or for Quantum:
quantum: [cron: [enabled: true]],
]
If you're using another library or a custom solution for scheduling jobs, you'll need to instrument those jobs manually.
Check-in monitoring allows you to track a job's progress by completing two check-ins: one at the start of your job, and another at the end of your job. This two-step process allows Sentry to notify you if your job didn't start when expected (missed) or if it exceeded its maximum runtime (failed).
{:ok, check_in_id} = Sentry.capture_check_in(status: :in_progress, monitor_slug: "<monitor-slug>")
# Execute your scheduled task here
my_scheduled_job()
Sentry.capture_check_in(check_in_id: check_in_id, status: :ok, monitor_slug: "<monitor-slug>")
If your job execution fails, you can notify Sentry about the failure:
Sentry.capture_check_in(check_in_id: check_in_id, status: :error, monitor_slug: "<monitor-slug>")
Heartbeat monitoring notifies Sentry of a job's status through a single check-in. This setup will only notify you if your job didn't start when expected (missed). If you need to track a job to see if it exceeded its maximum runtime (failed), use check-ins instead.
Sentry.capture_check_in(status: :ok, monitor_slug: "<monitor-slug>")
If your job execution fails, you can notify Sentry about the failure:
Sentry.capture_check_in(status: :error, monitor_slug: "<monitor-slug>")
You can create and update your monitors programmatically with code rather than creating and configuring them in Sentry.
To do that, you need to pass a :monitor_config set of options to Sentry.capture_check_in/3:
# Create a config from a crontab schedule (every 10 minutes)
monitor_config = [
schedule: [
type: :crontab,
value: "5 * * * *",
],
checkin_margin: 5, # Optional check-in margin in minutes
max_runtime: 15, # Optional max runtime in minutes
timezone: "Europe/Vienna", # Optional timezone
]
# Alternatively, create a config from an interval schedule (every 10 minutes in this case):
monitor_config = [
schedule: [
type: :interval,
unit: :minute,
value: 10
],
checkin_margin: 5, # Optional check-in margin in minutes
max_runtime: 15, # Optional max runtime in minutes
timezone: "Europe/Vienna", # Optional timezone
]
# Notify Sentry your job is running:
{:ok, check_in_id} =
Sentry.capture_check_in(
status: :in_progress,
monitor_slug: "<monitor-slug>",
monitor_config: monitor_config
)
# Execute your job:
execute_job()
# Notify Sentry your job has completed successfully:
Sentry.capture_check_in(
status: :ok,
check_in_id: check_in_id,
monitor_slug: "<monitor-slug>",
monitor_config: monitor_config
)
When your recurring job fails to check in (missed), runs beyond its configured maximum runtime (failed), or manually reports a failure, Sentry will create an error event with a tag connected to your monitor.
To receive alerts about these events:
- Navigate to Alerts in the sidebar.
- Create a new alert and select "Issues" under "Errors" as the alert type.
- Configure your alert and define a filter match to use:
The event's tags match {key} {match} {value}.
Example: The event's tags match monitor.slug equals my-monitor-slug-here
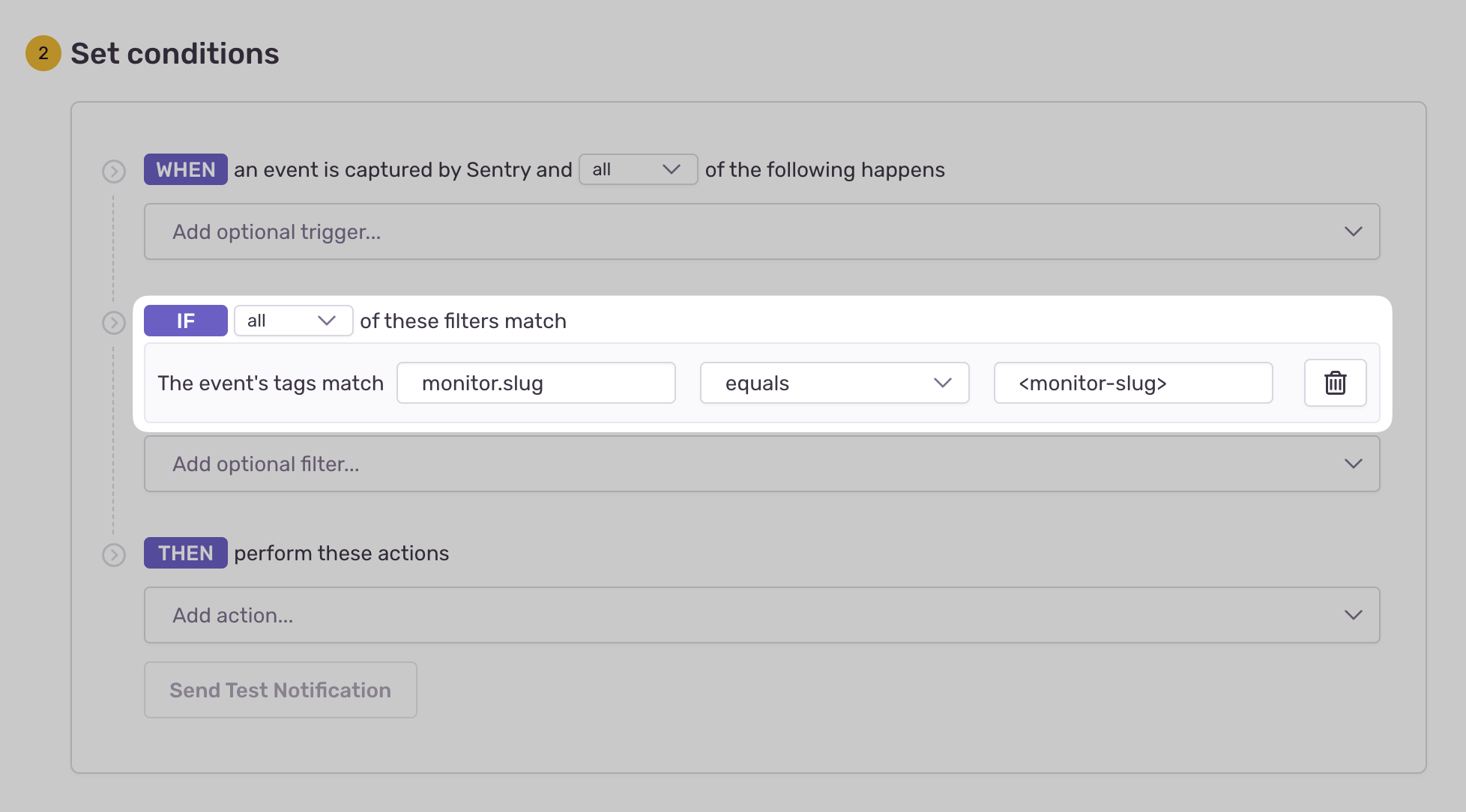
Learn more in Issue Alert Configuration.
Crons imposes a rate limit on check-ins to prevent abuse and resource overuse. Specifically, you can only send a maximum of 6 check-ins per minute per existing monitor environment. This limit is enforced on a per-project basis, meaning that the rate limit applies collectively to all monitor environments within a given project. You can check if any of your check-ins are being dropped in the Usage Stats page.
To avoid dropped check-ins, it is crucial to manage and distribute your check-ins efficiently within the rate limits. This will help maintain accurate monitoring and ensure that all critical check-ins are captured and processed.
Our documentation is open source and available on GitHub. Your contributions are welcome, whether fixing a typo (drat!) or suggesting an update ("yeah, this would be better").